STL中学习总结
STL学习
缘起:
在学习图算法的过程中,因为图的数据结构中要用到C++中STL的基本知识,但是实际使用的过程中,发现对STL的一些使用很陌生,这里做一下笔记记录。
1 unordered_set
《算法》这本书中的Bag的数据结构,使用unordered_set实现。
邻接链表表示为 std::vector<<std::unordered_set>>
vector 存放节点的序号
unordered_set 存放每个节点的相邻节点
unordered_set 底层实现都采用的是哈希表存储结构,只有前向迭代器,没有反向迭代器。
哈希表也成为散列表,参考《算法》第三章散列表章节
具体原理参考
http://c.biancheng.net/view/7235.html
http://c.biancheng.net/view/3437.html
相应的成员函数
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end(); | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_set 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_set 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回 unordered_set 容器中当前的负载因子。负载因子,指的是的当前容器中存储元素的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_set 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳 count 个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
2 stack
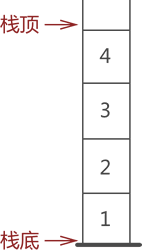
栈是先入后出的数据结构。
栈是一种只能从表的一端存取数据且遵循 “先进后出” 原则的线性存储结构。
通常,栈的开口端被称为栈顶;相应地,封口端被称为栈底。
栈存储结构示意图

关于stack的博客
https://blog.51cto.com/u_15307009/5509563
3 quene
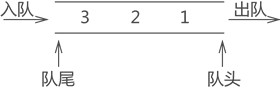
队列是先入先出的数据结构。
数据从表的一端进,从另一端出,且遵循 “先进先出” 原则的线性存储结构就是队列
通常,称进数据的一端为 “队尾”,出数据的一端为 “队头”,数据元素进队列的过程称为 “入队”,出队列的过程称为 “出队”。
4 set
用到了set的插入操作 insert
set删除一个元素 erase
5 优先队列
https://blog.51cto.com/u_10125763/5342409
https://blog.csdn.net/qq_37454669/article/details/123782139
6 lower_bound与upper_bound函数使用
lower_bound( )函数与upper_bound( )函数的使用,包括调用默认比较函数和自定义比较函数的用法,自定义比较函数主要是lambda表达式。
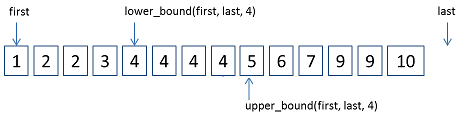
lower_bound( )函数与upper_bound( )函数都是基于二分搜索操作的函数,其操作对象是有序的。lower_bound( )函数返回指向第一个不小于给定值的元素的迭代器,upper_bound( )函数返回指向第一个大于给定值的元素的迭代器。
对这两个函数的理解,一图胜千言。
6.1 使用自定义比较函数
自定义的比较函数,可以是自己重载的operator<函数,也可以是仿函数,纯比较函数,或者lambda表达式。下面,我采用lambda进行说明。
现在假设我们定义了一个自己的类Integer。然后我们使用lambda表达式作为自定义的比较函数。自定义的类如下:
struct Integer
{
int value_=0;
Integer() = default;
Integer(int value) :value_(value)
{}
};
具体示例:
int main()
{
vector<Integer> data{ {1},{2},{4},{5},{5},{6} };
for (int i = 0; i < 8; i++)
{
auto iter = lower_bound(data.begin(), data.end(), Integer(i),
[](const Integer& val, const Integer& ele)
{
return val.value_ < ele.value_;
}
);
if (iter != data.end())
{
cout << "首个不小于" << i << "的元素的索引为:" << distance(data.begin(), iter);
cout << " 该元素为:" << iter->value_ << '\n';
}
else
{
cout << "data中不存在不小于" << i << "的元素\n";
}
}
}
在这个例子中,我们用Integer对象和int比较的时候,将int构造了一个临时的Integer对象。但是如果我们直接让这两者比较呢?这里需要注意:在这种情况下,lower_bound函数和upper_bound函数中lambda表达式的写法有所不同。
auto lower = lower_bound(data.begin(), data.end(), i, [](const Integer& ele,int val)
{
return ele.value_<val;
}
);
//注意参数的顺序
auto upper = upper_bound(data.begin(), data.end(), i, [](int val, const Integer& ele)
{
return val < ele.value_;
}
);
可以发现,在lower_bound中,我们应该把int类型的参数放在第二个参数的位置,在调用的时候,val=i。而upper_bound则是相反的。
6.2 STL源码解析
6.2.1 upper_bound函数
/**
* 以下程序来自:bits/stl_algobase.h
*
* @brief 找到最后一个可以插入 __val 的位置,而且不改变原来的排序
* @ingroup binary_search_algorithms,二分查找算法
* @param __first An iterator. 一个迭代器
* @param __last Another iterator. 另一个迭代器
* @param __val The search term. 寻找的项
* @return An iterator pointing to the first element greater than @p __val,
* or end() if no elements are greater than @p __val.
* 拿到一个迭代器,指向第一个大于 __val 元素的地方,
* 如果没找到大于 __val 的元素,那么就返回 end()
* @ingroup binary_search_algorithms
*/
template<typename _ForwardIterator, typename _Tp>
inline _ForwardIterator
upper_bound(_ForwardIterator __first, _ForwardIterator __last,
const _Tp &__val) {
// concept requirements
__glibcxx_function_requires(_ForwardIteratorConcept < _ForwardIterator >)
__glibcxx_function_requires(_LessThanOpConcept <
_Tp, typename iterator_traits<_ForwardIterator>::value_type >)
__glibcxx_requires_partitioned_upper(__first, __last, __val);
return std::__upper_bound(__first, __last, __val,
__gnu_cxx::__ops::__val_less_iter());
}
/**
* 以下程序来自:bits/stl_algobase.h
*/
template<typename _ForwardIterator, typename _Tp, typename _Compare>
_ForwardIterator
__upper_bound(_ForwardIterator __first, _ForwardIterator __last,
const _Tp &__val, _Compare __comp) {
typedef typename iterator_traits<_ForwardIterator>::difference_type
_DistanceType;
_DistanceType __len = std::distance(__first, __last);
/**
* 下面使用二分查找算法来实现
* __len 右指针
* __first 左指针
* __middle 中间值
*/
while (__len > 0) {
_DistanceType __half = __len >> 1; // __len / 2 操作,位移操作更快
_ForwardIterator __middle = __first;
std::advance(__middle, __half);
if (__comp(__val, __middle))
__len = __half;
else {
__first = __middle;
++__first;
__len = __len - __half - 1;
}
}
return __first;
}
/**
* @brief Finds the last position in which @p __val could be inserted
* without changing the ordering.
* @ingroup binary_search_algorithms
* @param __first An iterator.
* @param __last Another iterator.
* @param __val The search term.
* @param __comp A functor to use for comparisons.
* @return An iterator pointing to the first element greater than @p __val,
* or end() if no elements are greater than @p __val.
* @ingroup binary_search_algorithms
*
* The comparison function should have the same effects on ordering as
* the function used for the initial sort.
*/
template<typename _ForwardIterator, typename _Tp, typename _Compare>
inline _ForwardIterator
upper_bound(_ForwardIterator __first, _ForwardIterator __last,
const _Tp &__val, _Compare __comp) {
// concept requirements
__glibcxx_function_requires(_ForwardIteratorConcept < _ForwardIterator >)
__glibcxx_function_requires(_BinaryPredicateConcept < _Compare,
_Tp, typename iterator_traits<_ForwardIterator>::value_type >)
__glibcxx_requires_partitioned_upper_pred(__first, __last,
__val, __comp);
return std::__upper_bound(__first, __last, __val,
__gnu_cxx::__ops::__val_comp_iter(__comp));
}
具体使用
int main() {
vector<int> nums = {1, 2, 3, 4, 4, 5};
cout <<
*upper_bound(nums.begin(), nums.end(), 3) << endl; // >: 4
cout <<
upper_bound(nums.begin(), nums.end(), 3) - nums.begin() << endl; // >: 3
}
int main() {
vector<int> nums = {1, 2, 3, 4, 4, 5};
cout <<
*upper_bound(nums.begin(), nums.end(), 3) << endl; // >: 4
cout <<
upper_bound(nums.begin(), nums.end(), 3) - nums.begin() << endl; // >: 3
cout << *lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val <= b;
}) << endl; // >: 4
cout << lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val <= b;
}) - nums.begin() << endl; // >: 3
}
6.2.2 lower_bound函数
/**
* @brief Finds the first position in which @a val could be inserted
* without changing the ordering.
* @param __first An iterator.
* @param __last Another iterator.
* @param __val The search term.
* @return An iterator pointing to the first element not less
* than(不小于!!!也就是大于等于) @a val, or end() if every element is less than
* @a val.
* @ingroup binary_search_algorithms
*/
template<typename _ForwardIterator, typename _Tp>
inline _ForwardIterator
lower_bound(_ForwardIterator __first, _ForwardIterator __last,
const _Tp &__val) {
// concept requirements
__glibcxx_function_requires(_ForwardIteratorConcept < _ForwardIterator >)
__glibcxx_function_requires(_LessThanOpConcept <
typename iterator_traits<_ForwardIterator>::value_type, _Tp >)
__glibcxx_requires_partitioned_lower(__first, __last, __val);
return std::__lower_bound(__first, __last, __val,
__gnu_cxx::__ops::__iter_less_val());
}
template<typename _ForwardIterator, typename _Tp, typename _Compare>
_ForwardIterator
__lower_bound(_ForwardIterator __first, _ForwardIterator __last,
const _Tp &__val, _Compare __comp) {
typedef typename iterator_traits<_ForwardIterator>::difference_type
_DistanceType;
_DistanceType __len = std::distance(__first, __last);
while (__len > 0) {
_DistanceType __half = __len >> 1;
_ForwardIterator __middle = __first;
std::advance(__middle, __half);
if (__comp(__middle, __val)) { // 也正是这里的不同导致了两个函数功能的不同~
__first = __middle;
++__first;
__len = __len - __half - 1;
} else
__len = __half;
}
return __first;
}
示例源码:
int main() {
vector<int> nums = {1, 2, 3, 4, 4, 5};
cout <<
*upper_bound(nums.begin(), nums.end(), 3) << endl; // >: 4
cout <<
upper_bound(nums.begin(), nums.end(), 3) - nums.begin() << endl; // >: 3
cout << *lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val <= b;
}) << endl; // >: 4
cout << lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val <= b;
}) - nums.begin() << endl; // >: 3
}
两个函数的示例源码:
/**
* Created by Xiaozhong on 2020/9/20.
* Copyright (c) 2020/9/20 Xiaozhong. All rights reserved.
*/
#include "iostream"
#include "vector"
#include "algorithm"
using namespace std;
int main() {
vector<int> nums = {1, 2, 3, 4, 4, 5};
cout <<
*upper_bound(nums.begin(), nums.end(), 3) << endl; // >: 4
cout <<
upper_bound(nums.begin(), nums.end(), 3) - nums.begin() << endl; // >: 3
cout << *upper_bound(nums.begin(), nums.end(), 3, [&](const int &val, const int &b) {
/**
* 参数 val 就是 3
* 参数 b 来自 nums 中的数
*/
return val < b;
}) << endl; // >: 4
cout <<
*lower_bound(nums.begin(), nums.end(), 3) << endl; // >: 3
cout <<
lower_bound(nums.begin(), nums.end(), 3) - nums.begin() << endl; // >: 2
cout << *lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val < b;
}) << endl; // >: 3
cout << *lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val <= b;
}) << endl; // >: 4
cout << lower_bound(nums.begin(), nums.end(), 3, [](const int &val, const int &b) {
return val <= b;
}) - nums.begin() << endl; // >: 3
}
7 迭代器
7.1 迭代器种类
| 种类 | 定义方法 |
|---|---|
| 正向迭代器 | 容器类名::iterator 迭代器名; eg: std::vector |
| 常量正向迭代器 | 容器类名::const_iterator 迭代器名; eg: std::vector |
| 反向迭代器 | 容器类名::reverse_iterator 迭代器名; eg: std:vector |
| 常量反向迭代器 | 容器类名::const_reverse_iterator 迭代器名; eg: std::vector |
7.2 迭代器用法示例
通过迭代器可以读取它指向的元素,*迭代器名就表示迭代器指向的元素。通过非常量迭代器还能修改其指向的元素。
迭代器都可以进行++操作。反向迭代器和正向迭代器的区别在于:
- 对正向迭代器进行
++操作时,迭代器会指向容器中的后一个元素; - 而对反向迭代器进行
++操作时,迭代器会指向容器中的前一个元素。
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v; //v是存放int类型变量的可变长数组,开始时没有元素
for (int n = 0; n<5; ++n)
v.push_back(n); //push_back成员函数在vector容器尾部添加一个元素
vector<int>::iterator i; //定义正向迭代器
for (i = v.begin(); i != v.end(); ++i) { //用迭代器遍历容器
cout << *i << " "; //*i 就是迭代器i指向的元素
*i *= 2; //每个元素变为原来的2倍
}
cout << endl;
//用反向迭代器遍历容器
for (vector<int>::reverse_iterator j = v.rbegin(); j != v.rend(); ++j)
cout << *j << " ";
return 0;
}
7.3 迭代器功能分类
不同容器的迭代器,其功能强弱有所不同。容器的迭代器的功能强弱,决定了该容器是否支持 STL 中的某种算法。例如,排序算法需要通过随机访问迭代器来访问容器中的元素,因此有的容器就不支持排序算法。
常用的迭代器按功能强弱分为输入、输出、正向、双向、随机访问五种,这里只介绍常用的三种。
\1) 正向迭代器。假设 p 是一个正向迭代器,则 p 支持以下操作:++p,p++,*p。此外,两个正向迭代器可以互相赋值,还可以用==和!=运算符进行比较。
\2) 双向迭代器。双向迭代器具有正向迭代器的全部功能。除此之外,若 p 是一个双向迭代器,则--p和p--都是有定义的。--p使得 p 朝和++p相反的方向移动。
\3) 随机访问迭代器。随机访问迭代器具有双向迭代器的全部功能。若 p 是一个随机访问迭代器,i 是一个整型变量或常量,则 p 还支持以下操作:
- p+=i:使得 p 往后移动 i 个元素。
- p-=i:使得 p 往前移动 i 个元素。
- p+i:返回 p 后面第 i 个元素的迭代器。
- p-i:返回 p 前面第 i 个元素的迭代器。
- p[i]:返回 p 后面第 i 个元素的引用。
此外,两个随机访问迭代器 p1、p2 还可以用 <、>、<=、>= 运算符进行比较。p1<p2的含义是:p1 经过若干次(至少一次)++操作后,就会等于 p2。其他比较方式的含义与此类似。
对于两个随机访问迭代器 p1、p2,表达式p2-p1也是有定义的,其返回值是 p2 所指向元素和 p1 所指向元素的序号之差(也可以说是 p2 和 p1 之间的元素个数减一)。
表1所示为不同容器的迭代器的功能。
| 容器 | 迭代器功能 |
|---|---|
| vector | 随机访问 |
| deque | 随机访问 |
| list | 双向 |
| set / multiset | 双向 |
| map / multimap | 双向 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priority_queue | 不支持迭代器 |
7.4 迭代器的辅助函数
STL 中有用于操作迭代器的三个函数模板,它们是:
- advance(p, n):使迭代器 p 向前或向后移动 n 个元素。
- distance(p, q):计算两个迭代器之间的距离,即迭代器 p 经过多少次 + + 操作后和迭代器 q 相等。如果调用时 p 已经指向 q 的后面,则这个函数会陷入死循环。
- iter_swap(p, q):用于交换两个迭代器 p、q 指向的值。
要使用上述模板,需要包含头文件 algorithm。下面的程序演示了这三个函数模板的 用法。
#include <list>
#include <iostream>
#include <algorithm> //要使用操作迭代器的函数模板,需要包含此文件
using namespace std;
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
list <int> lst(a, a+5);
list <int>::iterator p = lst.begin();
advance(p, 2); //p向后移动两个元素,指向3
cout << "1)" << *p << endl; //输出 1)3
advance(p, -1); //p向前移动一个元素,指向2
cout << "2)" << *p << endl; //输出 2)2
list<int>::iterator q = lst.end();
q--; //q 指向 5
cout << "3)" << distance(p, q) << endl; //输出 3)3
iter_swap(p, q); //交换 2 和 5
cout << "4)";
for (p = lst.begin(); p != lst.end(); ++p)
cout << *p << " ";
return 0;
}
8 vector
对于vector和string,如果需要更多空间,就以类似realloc的思想来增长大小。这个类似于realloc的操作有四个部分:
- 分配新的内存块,它有容器目前容量的倍数。在大部分实现中,vector和string的容量每次以2为因数增长。也就是说,当容器必须扩展时,它们的容量每次翻倍。
- 把所有元素从容器的旧内存拷贝到它的新内存。
- 销毁旧内存中的对象。
- 回收旧内存。
#include <stdint.h>
#include <iostream>
#include <vector>
using namespace std;
void growPushBack(vector<int> &vec, uint16_t size) {
for (int i = 0; i < 100; i++) {
vec.push_back(i);
if (size != vec.capacity()) {
size = vec.capacity();
cout << "Capacity changed: " << size << endl;
}
}
}
int main() {
uint16_t sz = 0;
vector<int> vecIntA;
sz = vecIntA.capacity();
// 声明vector后未使用reserve,直接进行push_back操作
cout << "Making vecIntA growing:" << endl;
growPushBack(vecIntA, sz);
cout << "\n========separator========\n" << endl;
vector<int> vecIntB;
sz = vecIntB.capacity();
// 声明vecIntB后用reserve来执行其容量为100
vecIntB.reserve(100);
cout << "Making vecIntB growing: " << endl;
growPushBack(vecIntB, sz);
return 0;
}
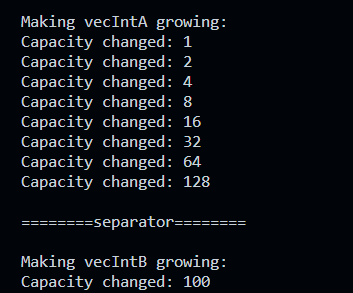
上述程序的运行结果,显示vector分配大小是按照1->2->4->8->16->32->64->128