操作系统模块-文件系统学习笔记
关于文件系统的学习笔记
- 《现代操作系统:原理与实现》第9章读书笔记
- 《操作系统导论》第40章 读书笔记
第九章
文件是操作系统进行存储时使用最多的抽象之一。
每个文件实质上是一个有名字的字符序列。序列的内容为文件数据(file data)。
文件元数据(file metadata):序列长度、序列的修改时间等描述文件数据的属性、支撑文件功能的其他信息称为文件元数据。
文件名用于区分不同的文件,通常保存在目录中。
目录将文件名组织在一起,并且记录了每个文件名对应的文件地址或者编号。
每个文件名和对应的文件地址或编号组成一个目录项,一个或多个目录项组成一个目录。
一般情况下目录被设计成一个特殊的文件,应用程序需要使用专门的接口来操作目录。
实现文件接口并负责管理文件数据和元数据的系统,称为文件系统。
9.1 基于inode的文件系统
9.1.1 inode与文件
inode是用来记录磁盘块的一种结构。inode是”index node”的缩写,即“索引节点”,记录了一个文件所对应的所有存储块号(即存储的索引)。
每个inode对应一个文件,通过一个inode,就可以访问这个文件的所有数据。
假设块大小为4kb,每个指针占据8个字节,每个inode中直接指针有12个,间接指针有3个,二级指针有1个。
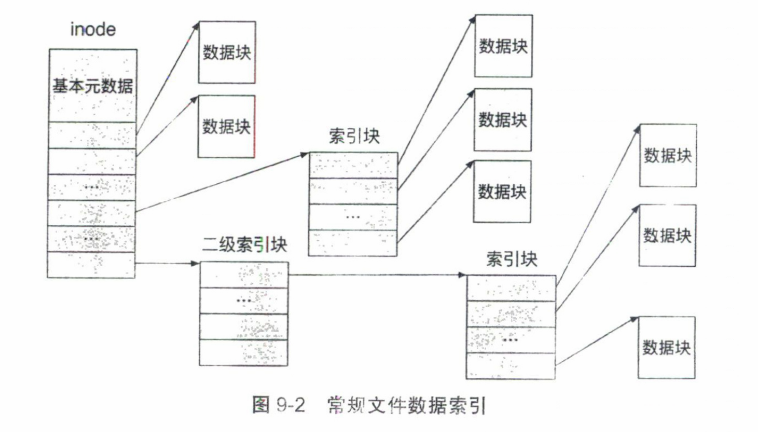 直接指针可以管理总共48kb的数据,如果一个文件超过48kb,则需要使用间接指针。
直接指针可以管理总共48kb的数据,如果一个文件超过48kb,则需要使用间接指针。
一个间接指针,指向的索引块是512个,每个数据块是4kb,总共2MB数据,3个间接指针总共管理6MB数据。
一个二级间接指针,管理512个间接指针,512*2MB=1G。
因此目前的inode节点,总共管理的最大文件大小为 48KB+6MB+1GB。
我们可以通过调整inode的设计来改变其所能管理的最大文件大小。
 一个文件系统会支持多种文件类型。
一个文件系统会支持多种文件类型。
9.1.2 文件名与目录
文件与inode是一一对应的。对于用户来说,使用inode号作为文件名进行记忆比较困难。
使用inode号直接表示文件还会造成inode号与文件存储位置的强耦合。
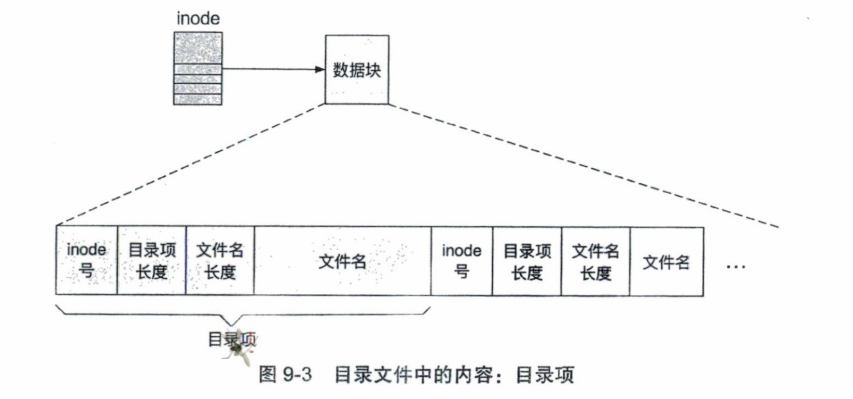
目录是一种特殊类型的文件,记录了从文件名到inode号的映射。目录中保存的是一种特殊的结构——目录项。
每个目录项代表一条文件信息,记录了文件的文件名及其对应的inode号。
9.1.3 硬链接与符号链接
硬链接
由于文件名并不是文件的元数据,因此一个文件可以对应多个文件名,即多个目录项可以指向同一个文件。
在Linux中可以通过 下面的命令为文件file创建另外一个名字link。
ln file link
这里link就是file的硬链接。
当用户创建了一个新的硬链接时,文件系统并不会创建一个新的inode,而是先找到目标文件的inode,随后在目标路径的父目录中增加一个指向此inode的新目录项。
从文件系统角度看,file和 link没有任何区别。可以类别C++中的引用。
符号链接
符号链接(symbolic link)又称为软链接(soft link),是一种特殊的文件类型。
Linux中可以通过下面的命令创建软链接。
ln -s file slink
符号链接文件中保存的是一个字符串。表示一个文件路径。
9.1.4 存储布局
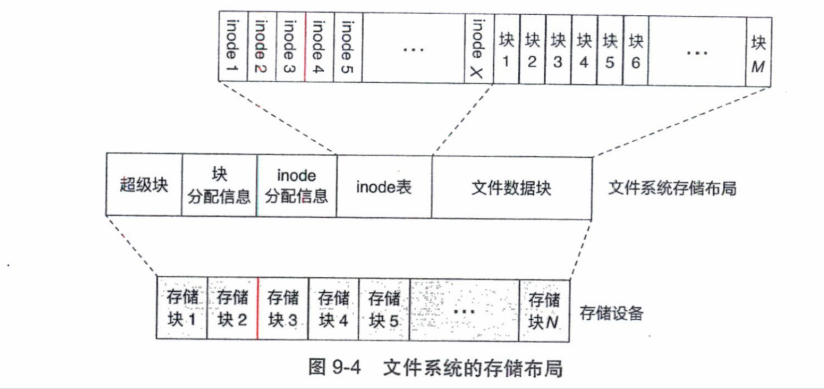
- 超级块:记录了整个文件系统的全局元数据。魔法数字是保存在超级块中比较重要的元数据之一。 不同的文件系统通常使用不同的魔法数字。
- 块分配信息:使用位图(bitmap)的格式标记文件数据块区域中各个块的使用情况。块分配信息区域中每个比特位,对应文件数据块区域中的一个块。比特位为1,则表示对应的数据块已经被分配和使用;若为0,则表示对应的数据块空闲。
- inode分配信息:表示每个inode的使用情况
- inode表:inode表以数组的形式保存了整个文件系统中所有的inode结构。文件系统通常使用inode在此表中的索引对不同inode进行区分。由于inode表的大小在文件系统创建时已经固定,因此文件系统所能保存的最大文件数量也受此限制。
- 文件数据块:剩余的存储空间为文件数据块区域,用于保存文件的数据。
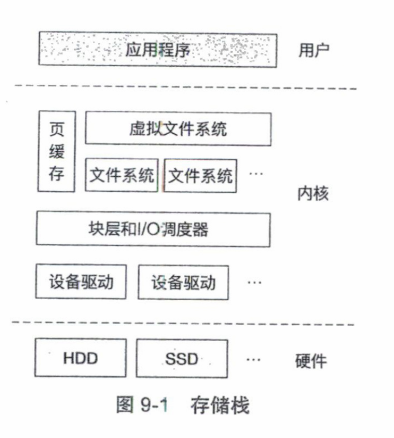
9.2 虚拟文件系统
在计算机系统中可能同时存在多种文件系统。在同一台计算机中,用户分别使用NTFS和Ext4两个文件系统管理一块机械硬盘上的不同区域。
用户还会将FAT32文件系统格式的USB闪存接入计算机系统中。
虚拟文件系统(Virtual File System,VFS)对多种文件系统进行管理和协调,允许它们在同一个操作系统上共同工作。
不同文件系统在存储设备上使用不同的数据结构和方法保存文件。
为了让这些文件系统工作在同一个操作系统上,VFS定义了一系列内存数据结构,并要求底层的不同文件系统提供指定的方法,然后利用这些方法将不同文件系统的元数据统一转换为VFS的内存数据结构。
VFS通过这些内存数据结构,向上为应用程序提供统一的文件系统服务。
9.2.1 面向文件系统的接口
VFS定义的内存数据结构 Linux的VFS基于inode制定了一系列的内存数据结构,包括超级块、inode、目录项等。
- VFS中的超级块
- VFS中的inode
- VFS中的文件数据管理
- VFS中的目录项
VFS定义的文件系统方法
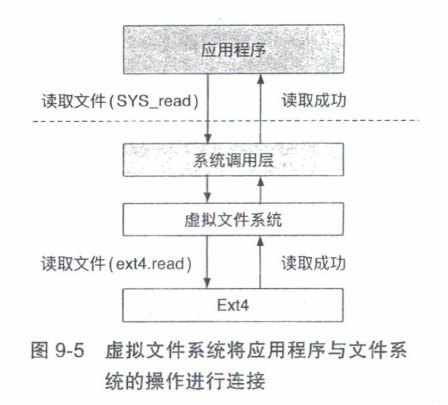 Linux中的VFS以函数指针的方式定义了文件系统应提供的方法。每个Linux中的文件系统均需要将其方法以函数指针的方式提供给VFS。
Linux中的VFS以函数指针的方式定义了文件系统应提供的方法。每个Linux中的文件系统均需要将其方法以函数指针的方式提供给VFS。
9.2.2 面向应用程序的接口
一个简单的文件访问程序
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#define DATA_SIZE 20
int main()
{
int fd;
char data[DATA_SIZE + 1];
//打开文件
fd = open("/home/chcore/filesystem.tex",
O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
// 读取文件中的前20个字节
read(fd, data, DATA_SIZE);
//打印文件中的前20个字节
data[DATA_SIZE] = '\0';
printf("file data: %s\n", data);
// 向文件中写入6个字节的数据
write(fd, "hello\n", 6);
//关闭文件
close(fd);
return 0;
}
路径解析
在程序执行的最开始,其首先使用open将文件路径转换成一个文件描述符,此后使用该文件描述符进行文件上的其他操作。
当程序调用open接口时,libc会将其转换成SYS_open系统调用,由内核中的VFS进行处理。VFS在处理SYS_open时,需要先解析应用程序提供的路径以找到对应文件,即路径解析。
在进行路径解析时,应用程序提供的路径被拆分成多个部分。每部分为一个文件名。
假定给定的路径为
/home/chcore/filesystem.tex
该路径被拆分为“home”“chcore”和”filesystem.tex”。由于路径是以”/”开头的绝对路径,路径查找从整个操作系统的根目录开始。
VFS首先在根目录中查找名为”chcore”的文件。在此过程中,VFS首先在其维护的各种缓存中进行查找。如果缓存中不存在此文件,则调用具体的文件系统接口进行查找。若文件系统中也无法找到该文件,则打开失败,返回路径不存在的错误消息给应用程序。
当”/home” 文件被找到之后,VFS还会进行一系列检查。如检查当前应用程序是否有访问该文件的权限、该文件是否为一个目录文件等。
若该文件是一个符号链接,VFS还需要先解析该符号链接,再继续后面的路径查找工作。
若该文件是一个挂载点,则还需更新当前路径的文件系统信息等。
在这些检查完毕后,VFS可以开始继续下一步查找,即在“home”目录中继续查找“出core”文件。
在路径解析完毕后,VFS得到了文件所对应的inode。然而VFS并不直接inode返回给应用程序,而是在其中增加了一层抽象,即文件描述符。
文件描述符
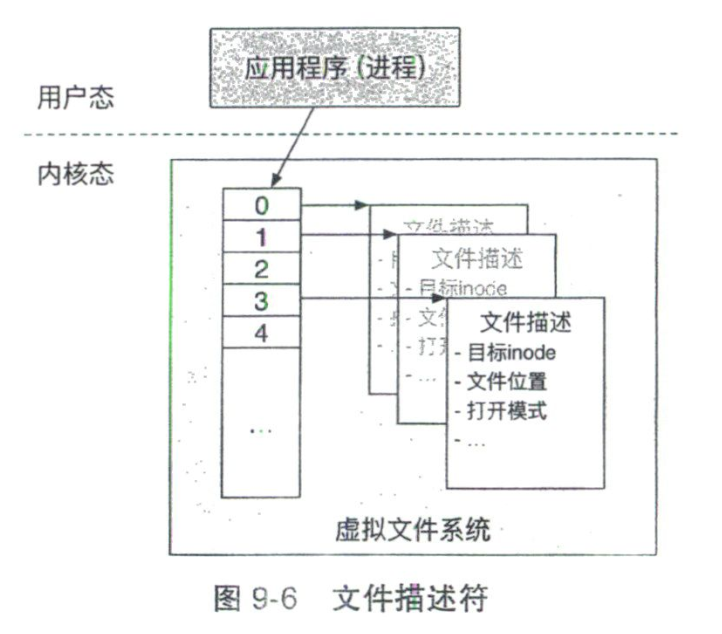 文件描述符实际上是一个整数。通常由VFS进行维护。VFS为操作系统中的每个进程维护一个文件描述符表,该表以文件描述符为索引,保存了一组文件描述结构。
文件描述符实际上是一个整数。通常由VFS进行维护。VFS为操作系统中的每个进程维护一个文件描述符表,该表以文件描述符为索引,保存了一组文件描述结构。
每个文件描述结构中记录了一个被打开文件的各种信息,如目标inode(即被打开文件的inode)、文件当前的读写位置和文件打开的模式等。
当VFS通过路径解析找到要打开的文件的inode后,VFS会分配一个文件描述符和对应的文件描述结构并进行初始化。VFS将inode信息记录在文件描述结构中,将文件读写位置设置为0,并将文件打开的模式也记录在文件描述结构中。最后,VFS将文件描述符返回给应用程序,表示文件已成功打开。
文件描述符是应用程序和操作系统之间建立起的一个认证关系。应用程序首先使用文件路径换取文件描述符,此后使用文件描述符对该文件进行其他操作。
文件描述符使得VFS无须每次都进行路径解析和各种检查操作,在一定程度上提高了效率。同时,通过维护文件描述符,操作系统可以监视和控制每个进程正打开的文件,对资源使用情况进行控制。
相对路径和当前工作目录
在没有指定工作目录时,VFS会默认使用每个进程的当前工作目录。VFS为每个进程维护了一个当前工作目录。应用程序可以通过getcwd和chdir获取和修改当前工作目录。
9.2.3 页缓存、直接I/O与内存映射
文件系统中的结构修改如果直接在存储设备进行,有两个问题:
首先,目前大多数存储设备都是块接口,读写粒度为一个数据块,大小通常为512字节或4096字节。文件系统所对应的更改往往并非是块对齐的,其读写的字节数也并非恰好为块的整数倍。
其次,存储设备的访问速度慢,与内存相比要慢几个数量级。大量频繁的存储设备访问操作会成为应用程序的性能瓶颈。
访问粒度不一致问题和一些优化
文件系统使用内存作为中转来解决访问粒度不一致的问题。
读取——修改——写回。
读取—— 修改1—— 修改2——修改3——…——修改n——写回。
读缓存
文件的访问具有时间局部性:当文件的一部分被访问后,有较高的概率其会再次被使用。当文件系统从设备中读取了某个文件的数据之后,可以让这些数据继续保留在内存中一段时间。当应用程序需要再次读取这些数据时,就可以从此前保留在内存中的数据中读取,从而避免了存储设备的访问。这就是文件系统的读缓存。
读缓存需要占用内存空间。为了防止读缓存占用过多内存,操作系统会对读缓存的大小进行限制。
写缓冲区与写合并
与读缓存相对应,是写缓冲区。
在一个文件写请求返回到应用程序之后,允许其修改的数据暂时不持久化到存储设备中。这个权衡允许文件系统暂时将修改的数据保存在内存中,并在后台慢慢地持久化到存储设备中。这样缺点是牺牲了一定的可靠性。
为了保证数据被持久化到设备中,POSIX中规定了fsync接口,用于保证某个已打开的文件的所有修改全部被持久化到存储设备中。
当文件系统修改完文件数据后,其修改会被暂存在写缓冲区的内存页中。如果后续的文件请求需要读取或者修改相同存储块中的数据,文件系统可以直接在写缓冲区对应的内存页上进行读取或者修改。
当可用内存不足,或者对应的fsync被调用时,写缓冲区内存页中的数据才被写回到存储设备对应的存储块中。
页缓存
在Linux内核中,读缓存与写缓冲区的功能被合并起来管理,称为页缓存。页缓存以内存页为单位,将存储设备中存储位置映射到内存中。文件系统通过调用VFS提供的相应接口对页缓存进行操作。
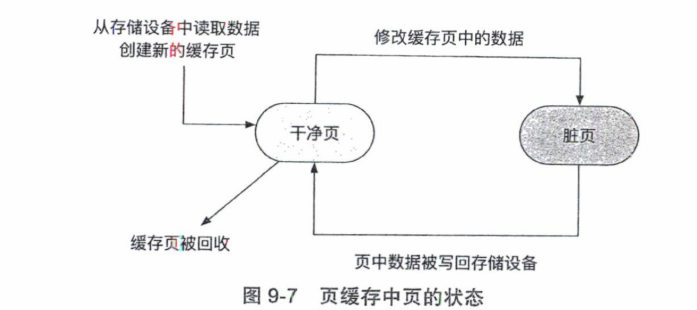 当一个文件被读取时,文件系统首先会检查其内容是否已经保存在页缓存中。
当一个文件被读取时,文件系统首先会检查其内容是否已经保存在页缓存中。
当进行文件修改时,文件系统同样首先会检查页缓存。
直接I/O和缓存I/O
页缓存是持久化和性能之间权衡的产物。
文件系统将是否使用页缓存的判断和选择权交给了应用程序。应用程序可以在打开文件时通过附带O_DIRECT标志,提示文件系统不要使用页缓存。这种文件访问方式就是直接I/O。
相对应的使用页缓存的文件请求称为缓存I/O
内存映射
应用程序可以通过内存映射,以访问内存的形式访问文件内容。Linux在其页缓存的基础上实现了文件的内存映射机制。
在建立内存映射前,应用程序先打开目标文件,获得其文件描述符。随后,应用程序通过mmap接口建立文件内存映射,调用时需提供映射的目标虚拟地址、长度、属性、标志位、文件描述符和起始位置在文件中的偏移量。
在处理内存映射请求时,VFS会分配对应的VMA结构,并通过在VMA结构中记录目标文件的inode和映射时的属性,将VMA对应的虚拟地址空间和文件inode进行关,最后返回起始虚拟地址给应用程序。
由于此时并未更新页表,当应用程序首次访问映射后的虚拟地址时,会触发缺页中断。Linux在处理缺页中断时,会根据VMA中记录的inode信息,调用对应的文件系统进行处理。文件系统将从文件的页缓存中找到对应的内存页返回给VFS。VFS最终将页缓存中内存页的物理地址填入页表,并返回到应用程序继续执行。由于页表中的映射已经建立,应用程序对同一个虚拟页的后续访问将不会触发缺页中断。
在进行内存映射之后,应用程序在进行访问时,访问的是页缓存对应的内存页。其修改的数据保存在页缓存中,可能并没有写回到存储设备上。因此,为了保证修改的数据被写回到存储设备上,应用程序需要调用msync接口,请求VFS对指定的内存映射区域进行同步写回操作。
9.2.4 多种文件系统的组织和管理
管理多种文件系统是VFS的一个重要职责。
Linux操作系统使用简单的链表结构,将其支持的所有文件系统保存起来,包括内嵌的文件系统和在运行时作为模块加载的文件系统。
挂载点
每个文件系统在设计时都会有其本身的内部结构。这些结构均会有一个固定的入口保存在超级块中,通常这个入口为文件的根目录。
每个文件系统都有自己的根目录,当应用程序想要同时想要访问多个文件系统时,如果将各个文件系统的文件系统结构结合起来呢?
有一种简单的方法可以将所有的文件系统放在固定的位置,并使其相互独立。在windows系统中,用C盘,D盘区分。这就是一个个挂载的文件系统。
Linux的VFS维护一个统一的VFS文件系统树。在操作系统启动时,会有一个根文件系统。这个根文件系统作为VFS文件系统树的基础。
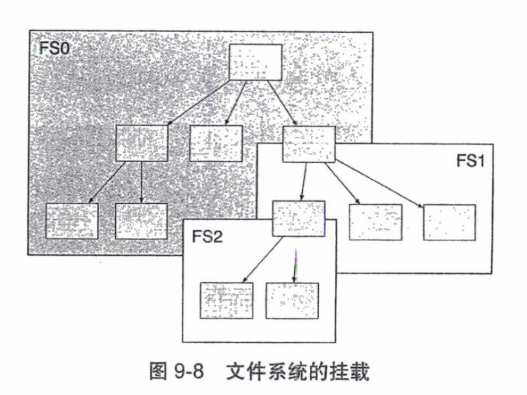 在根目录系统的基础上,其他的文件系统可以被自由地挂载到VFS文件书上的任何一个目录之上。这些作为挂载目标的目录,便被称为挂载点。
在根目录系统的基础上,其他的文件系统可以被自由地挂载到VFS文件书上的任何一个目录之上。这些作为挂载目标的目录,便被称为挂载点。
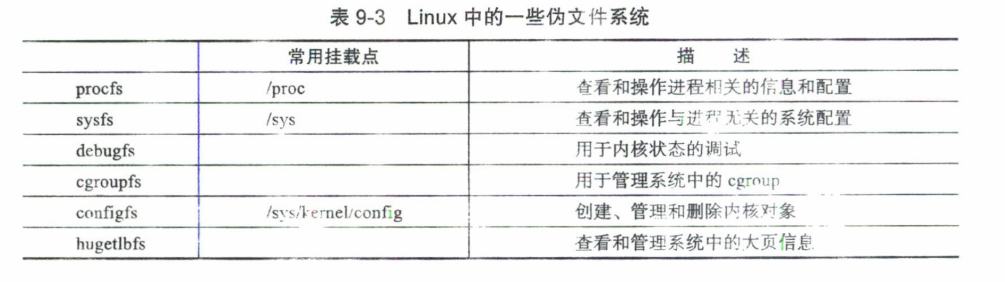
9.2.5 伪文件系统
Linux实现了一些不用于保存文件数据的文件系统,称为伪文件系统(pseudo file system)。
9.3 其他文件系统
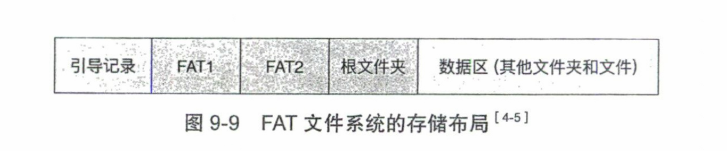
9.3.1 FAT文件系统
文件分配表(File Allocation Table,FAT)是一种组织文件系统的架构。
9.3.2 NTFS
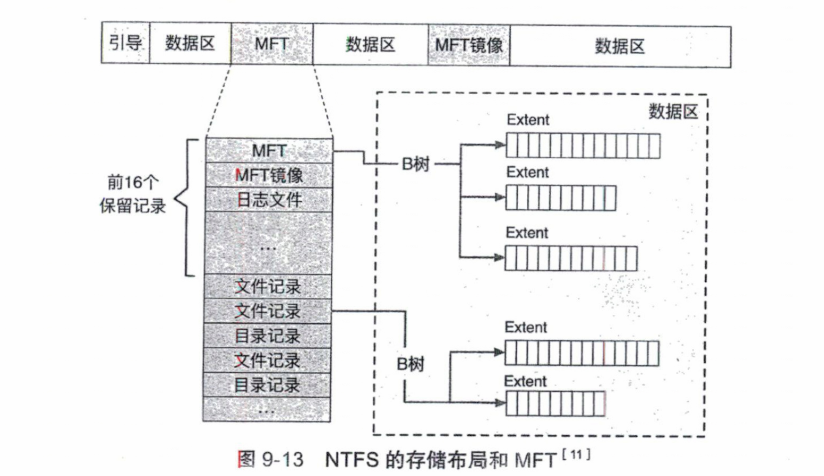
NTFS(New Technology File System, NTFS)是在FAT文件系统之后,另一个在Windows操作系统总广泛使用的文件系统。
存储布局与MFT
在NTFS中,文件系统的核心结构从FAT变成主文件表(Master File Table,MFT)
9.3.3 FUSE和用户态文件系统
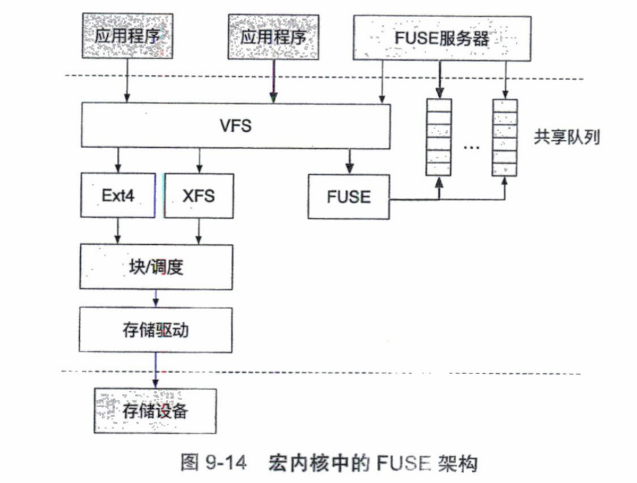
第40章 文件系统实现
作者对典型的UNIX文件系统做了简化,称为简单的文件系统实现,VSFS(Very Simple File System)。
文件系统是纯软件。没有硬件功能参与其中。
关键问题:如何实现简单的文件系统
- 如何构建一个简单的文件系统?
- 磁盘上需要什么结构?
- 它们需要记录什么?
- 它们如何访问?
40.1 思考方式
从两个方面来考虑文件系统的基本工作原理。
第一个方面是文件系统的数据结构。文件系统在磁盘上使用哪些类型的数据结构来组织其数据和元数据?
第二个方面是访问方法。 - 如何将进程发出的调用,如open()、read()、write()等,映射到它的结构上?
- 在执行特定的系统调用期间读取哪些结构?
- 改写那些结构?
- 所有这些步骤的执行效率如何?
40.2 整体组织
40.2.1 磁盘总体结构划分
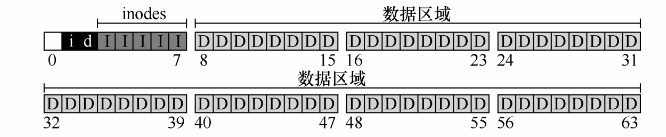
首先把磁盘分成块(block).VSFS只使用一种块大小,4KB。
这里假设一个很小的磁盘,只有64块,64*4KB=256KB。

40.2.2 数据区域
为了构建文件系统,这些块需要存储什么内容,首先就是用户数据。
数据区域:存放用户数据的磁盘区域。
这里将磁盘上64块中最后的56块分给数据区域。

40.2.3 inode节点
文件系统必须记录每个文件的信息。该信息是元数据(metadata)的关键部分。
inode节点记录以下内容: - 文件包含哪些数据块(在数据区域)
- 文件的大小
- 其所有者和访问权限
- 访问和修改时间以及其他类似的信息。
在磁盘上需要一定的空间存储inode,
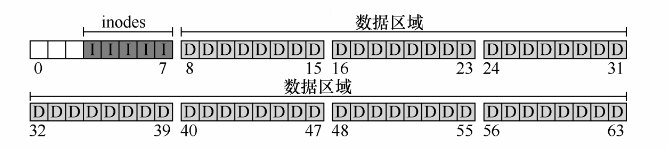
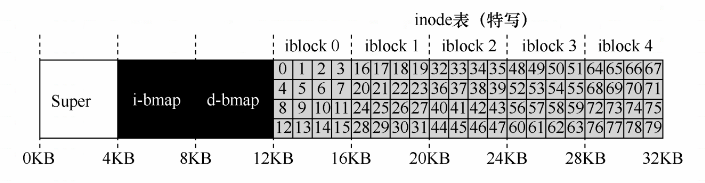
inode表:磁盘存放inode空间,是一个数组。假设,将64块中的5块用于inode。
 inode本身为128或256字节,假设每个inode节点是256字节。
inode本身为128或256字节,假设每个inode节点是256字节。
一个block块4KB可以容纳4KB/256B = 16 个inode。VSFS包含5个block,总共是5*16=80个inode。
inode的数量表示了简单文件系统能够拥有的最大文件数量。
40.2.4 位图
现在磁盘已经存放了数据区域和inode区域,还需要记录inode或者数据块是空闲还是已分配。
使用位图(bitmap):每个位表示相应的对象是空闲(0)还是正在使用(1)。
inode位图(i)和数据位图(d)
 位图示意图:
位图示意图:
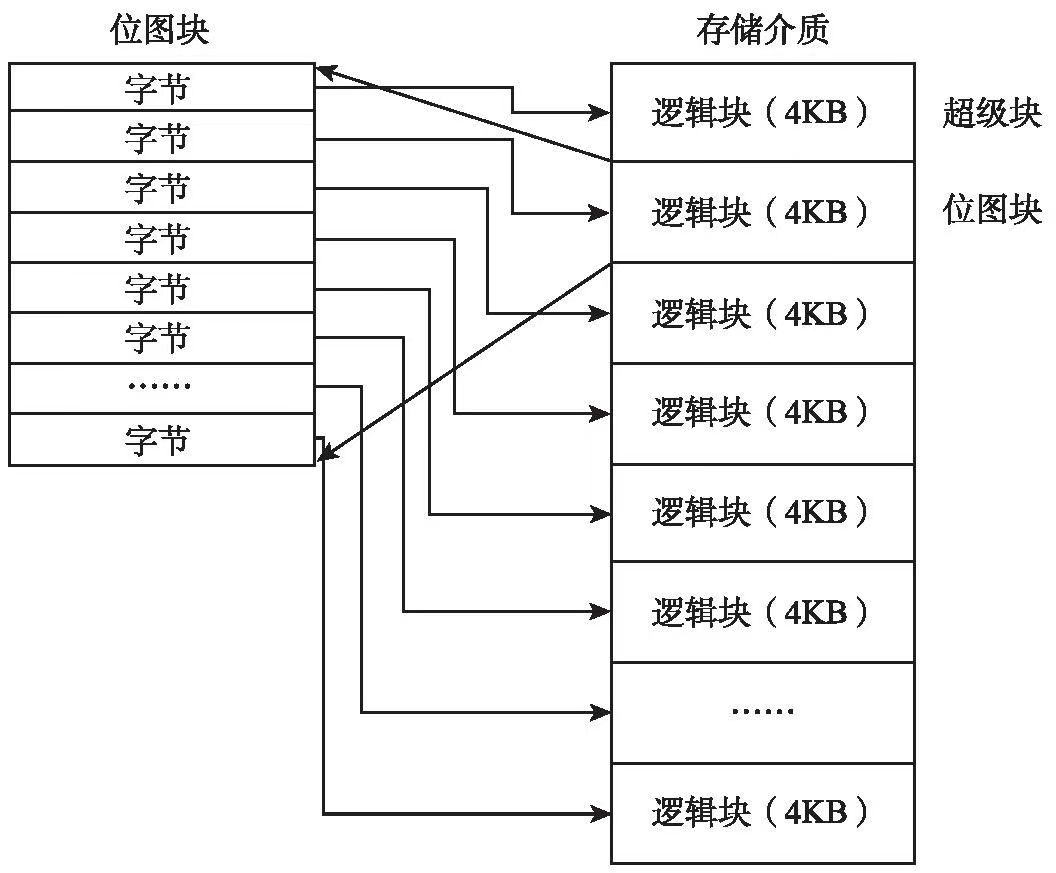 一个block块4KB,总共是4K×8bit = 32K bit,即82K对象是否分配。但在这里,我们只有80个inode和56个数据块。
一个block块4KB,总共是4K×8bit = 32K bit,即82K对象是否分配。但在这里,我们只有80个inode和56个数据块。
40.2.5 超级块
磁盘中还有一块区域留给了超级块(superblock)。
超级块包含关于该特定文件系统的信息:
- 文件系统包含的inode和数据块个数
- inode表的开始位置
- 幻数,标识文件系统
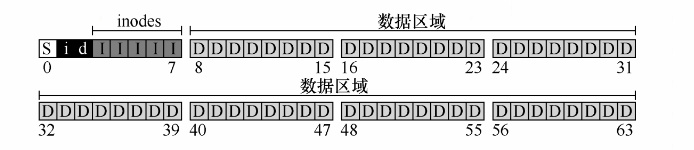 在挂载文件系统时,操作系统首先读取超级块,初始化各种参数,然后将该卷添加到文件系统树中。当卷中的文件被访问时,系统就会知道在哪里查找所需的磁盘上的结构。
在挂载文件系统时,操作系统首先读取超级块,初始化各种参数,然后将该卷添加到文件系统树中。当卷中的文件被访问时,系统就会知道在哪里查找所需的磁盘上的结构。
40.3 文件组织:inode
inode数据结构是许多文件系统使用的通用名称,用于描述保存给定文件的元数据的结构。UNIX开发人员设计的文件系统Ext给出的历史性名称。
每个inode由一个数字(inumber)引用。
 多级索引
inode节点中包含了一个i_block数组,该成员变量实际上存储了文件内容的一个块,用前12个块存放对应的文件数据,每个块4KB。
多级索引
inode节点中包含了一个i_block数组,该成员变量实际上存储了文件内容的一个块,用前12个块存放对应的文件数据,每个块4KB。
假设一个块是4KB,磁盘地址是4字节,一个块就可以存放4KB / 4B = 1024个指针,inode指向的文件就可以增加到 12 × 4KB + 10244KB = 4144KB。
如果还不够,还有二级指针。可以指向更大的文件。
124KB + 10244KB + 10241024*4KB = 44144KB > 4GB
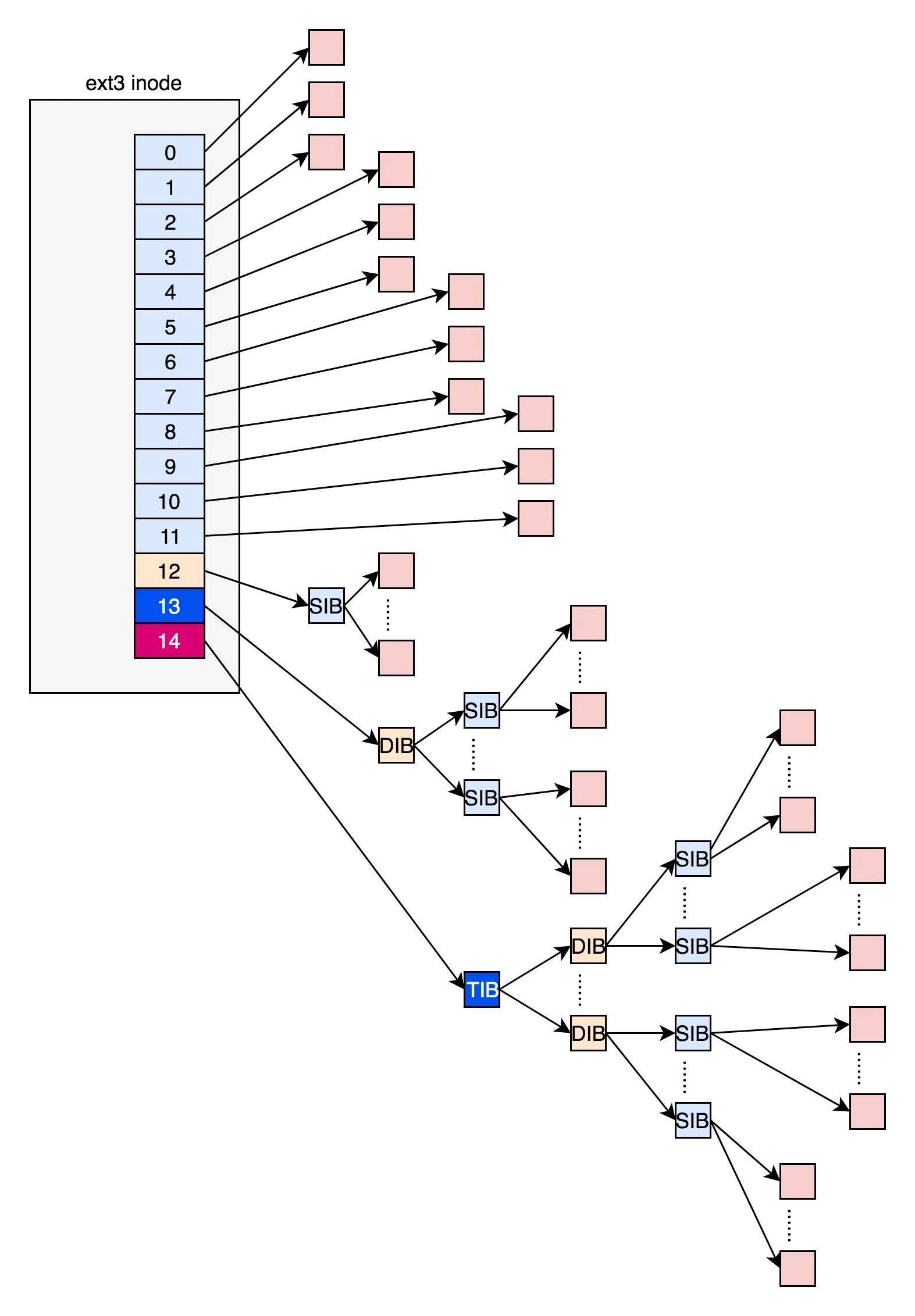 为什么要使用这样的不平衡树?
需要研究人员研究过文件系统及他们的使用方式。大多数文件很小。这种不平衡的设计反映了这样的现实。
为什么要使用这样的不平衡树?
需要研究人员研究过文件系统及他们的使用方式。大多数文件很小。这种不平衡的设计反映了这样的现实。
40.4 目录组织
UNIX哲学一切皆文件。
目录也是存放在数据区域,目录中包含一个二元组(条目名称,inode号)的列表。

40.5 空闲空间管理
文件系统必须记录哪些inode和数据块是空闲的,哪些不是,这样在分配新文件或目录时,就可以为它找到空间。这里使用位图表示。
40.6 访问路径:读取和写入
理解访问路径(acess path)上发生的事情是开发人员理解文件系统如何工作的第二个关键。
假设文件系统已经挂载,超级块已经在内存中。其他所有内容(inode,目录)仍在磁盘上。
40.6.1 从磁盘读取文件
给定一个例子:打开一个一个文件(/foo/bar/,读取它,然后关闭它)。
当你发出一个open(“/foo/bar”,O_RDONLY)调用时,文件系统首先需要找到文件bar的inode,从而获取该文件的一些基本信息(权限信息、文件大小等)。
文件系统必须遍历路径名,从而找到所需的inode。
所有的遍历都是从文件根目录开始,
文件系统第一次磁盘读取是根目录的inode节点。根的inode号必须是”众所周知“的。
在大多数UNIX文件系统中,根的inode号为2.
一旦inode被读入,文件系统就可以在其中查找指向数据块的指针,数据块包含根目录的内容。
下一步是递归遍历路径名,直到找到所需的inode。
open()的最后一步是将bar的inode读入内存,然后文件系统进行最后的权限检查,在每个进程的打开文件表中,为此进程分配一个文件描述符,并将它返回给用户。
40.6.2 写入磁盘
写入文件与读取不同的是,写入文件可能会分配(allocate)一个块。
当写入一个新文件时,每次写入操作不仅需要将数据写入磁盘,还必须首先决定将哪个块分配给文件,从而相应地更新磁盘的数据结构(例如数据位图和inode)。
每次写入文件在逻辑上导致5个I/O:
- 读取数据位图(更新以标记新分配的块被使用)
- 写入位图(将它的新状态存入磁盘)
- 读取inode位图
- 写入inode
- 写入真正的数据块本身
40.7 缓存和缓冲
读取和写入文件可能是昂贵的,会导致(慢速)磁盘的许多I/O.这是一个巨大的性能问题。大多数文件系统会积极使用内存来缓存重要的块。
现代操作系统将虚拟内存页面和文件系统页面集成到统一页面缓存中。
关于文件系统的学习
目前看了上海交大陈海波的《现代操作系统:原理与实现》,《Linux内核设计与实现》。
上海交大的操作系统书,写的比较清楚,后一本Linux设计与实现,看的不明白。
还有就是《操作系统导论》这本书非常的经典。
还看了彭东的嵌入式操作系统这本书,让我对位图有了一定的了解。
最近也看了不少视频,清华大学的操作系统课程。
小林coding博客关于文件系统这一部分,解释的还是蛮清楚的。
磁盘中存放的数据: 1 超级块 2 inode节点信息 3 数据块
查找路径的图例
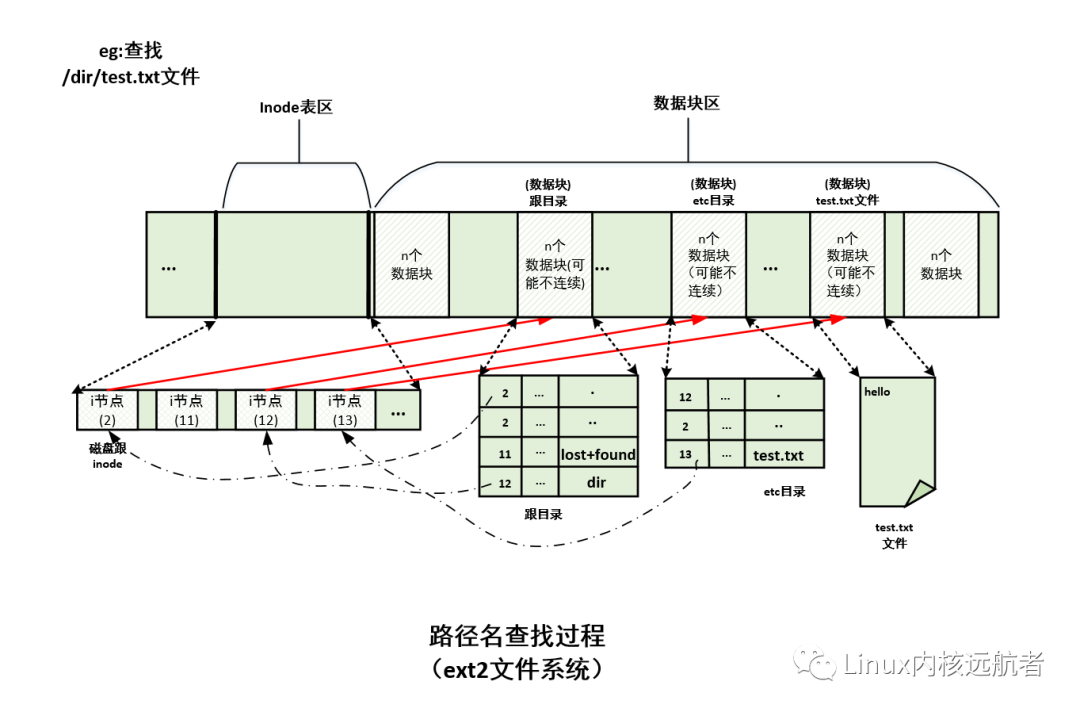 目录项并没有存放在磁盘中,而是加载到内存中,目录项存放的是<文件名,inode>。
只是为了在给定一个路径后,能够比较快地查找到inode节点。
目录项并没有存放在磁盘中,而是加载到内存中,目录项存放的是<文件名,inode>。
只是为了在给定一个路径后,能够比较快地查找到inode节点。